algoritmo de Ukkonen es un algoritmo on-line, con tiempo de computación lineal, para construir un árbol de sufijos de una cadena . Este algoritmo fue propuesto por Esko Ukkonen en 1995.

Anteriormente existían dos algoritmos capaces de construir el árbol de sufijos de una cadena en tiempo lineal, estos son el algoritmo de Weiner (1973) y el algoritmo de McCreight (1976). Pero el algoritmo de Ukkonen se destaca por ser más sencillo y por tener la característica de ser on-line.
Explicación del Algoritmo[editar]
Para explicar el algoritmo de Ukkonen partiremos de una implementación ingenua de este algoritmo que es a la cual se le hacen sucesivas mejoras hasta obtener el .


Sea el árbol de sufijos implícito de la cadena , con desde hasta , el algoritmo de Ukkonen aplicado a la cadena de longitud , construye sucesivamente . La ejecución del algoritmo de Ukkonen se divide en fases, en la fase se construye modificando , como el último carácter de es se cumple que es el árbol de sufijos de .

![{\displaystyle S[1..i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e5aeb3a1b0d8166cad66dd24c1ea5faeec430ae2)









Cada fase es a su vez dividida en extensiones. En la extensión -ésima de la fase se busca el final del camino desde la raíz etiquetado con la subcadena y se "extiende" dicho camino con el carácter .

![{\displaystyle S[j...i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/88e91fbe4abf1d1444c19dd039aa9d9d5b3688a1)
![{\displaystyle S[i+1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6108f9b661a1ef3de2a3726576ac63869b47de2d)
Reglas de extensión[editar]
A continuación se especifica cómo se realizan las extensiones.
Sea un sufijo de . En la extensión , el algoritmo encuentra el final de y lo extiende con el carácter de acuerdo a una de las siguientes reglas:
![{\displaystyle S[j..i]=a}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d9c121ba05d5febc0e8f61a2009b0348410c1686)

![{\displaystyle c=S[i+1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d1f16e953adeafe829768ed17cb4b93dd79e7a2a)
Regla 1: (Extensión en una hoja)
El camino de termina en una hoja. El carácter es añadido al final de la etiqueta de la arista incidente en dicha hoja.

Regla 2: (Extensión en una arista o nodo interno)
El camino de no termina en una hoja, pero ningún camino desde el final de inicia con el carácter . En este caso una nueva arista etiquetada con es creada desde el final de , dicha arista incide en una nueva hoja etiquetada con . Si termina en el interior de una arista, debe crearse además un nuevo nodo que corte dicha arista en el final de .
Regla 3: (El carácter c ya aparece, no hay que hacer nada) Algún camino desde el final de inicia con el carácter . No es necesario hacer nada.
Suffix links[editar]
Definición: Sea un nodo interno con etiqueta donde denota un carácter y denota un string posiblemente vacío, si existe otro nodo con etiqueta , entonces un puntero de a es llamado un suffix link y se denota .





Obsérvese que la definición no tiene sentido cuando es la raíz, pues esta no está etiquetada con una cadena de la forma .
Lema: Si al final de una fase, la cadena pertenece al árbol, entonces la cadena también pertenece.
Demostración: Si se insertó en la extensión de alguna fase , en la extensión de dicha fase se insertó .

Teorema: Si un nuevo nodo interno con etiqueta es añadido al árbol en la extensión de la fase , entonces se tendrá uno de los siguientes casos:
- El camino etiquetado termina en un nodo interno.
- En la extensión un nodo interno al final del camino a será creado.
Demostración: Un nuevo nodo es creado en la extensión de la fase solamente cuando la extensión ocurre en una arista (regla 2). Por tanto el camino etiquetado con continua con un carácter distinto de . Al inicio de la extensión , por el lema anterior, se cumple que hay un camino etiquetado con en el árbol y este continua con el carácter , (y posiblemente con otros caracteres). Si el camino etiquetado con continua con otros caracteres además de , entonces este ya termina en un nodo interno (primera situación del teorema). Por otra parte si el camino etiquetado con continua solamente con el carácter , entonces en la extensión , se aplicará la regla 2 y se creará un nodo interno al final de dicho camino (segunda situación del teorema).

Corolario: Al final de cada fase todos los nodos internos exceptuando la raíz tendrán un suffix link hacia otro nodo interno.
Usando los Suffix links para construir Ti+1[editar]
Recordemos que en la extensión de la fase el algoritmo localiza el sufijo de con , y luego realiza la extensión adecuada en dicho punto. Los suffix links se utilizarán para acortar el camino a la hora de localizar en el árbol. Las primera extensión se puede realizar macheando el string en el árbol, sin la ayuda de suffix links. Para realizar la extensión , debemos analizar los posibles casos donde ocurrió la extensión .
![{\displaystyle S[j..i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3c38fa3a40e295d0a368798835f44d8d89a52b25)

- Si ocurrió en un nodo interno (distinto de la raíz), este estará etiquetado con el string y tendrá un suffix link hacia un nodo etiquetado con el string (por ser un nodo interno distinto de la raíz, creado en una extensión anterior a la extensión de la fase ). Por tanto la extensión se realizará en el nodo .
![{\displaystyle xa=S[j..i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/af23c57da7086bd7d7a02c73ee51eb9349872267)
![{\displaystyle a=S[j+1..i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f6a52c07cd54972a1c7bcda84fed60162ae4e2d6)
- Si ocurrió en una hoja , sea el padre de , y sea la etiqueta de la arista . Si es la raíz, la extensión se debe realizar macheando la cadena desde la raíz. Por otra parte si no es la raíz, entonces tiene un suffix link hacia el nodo , para realizar la extensión , basta machear la cadena a partir de .



![{\displaystyle S[j+1..i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/401a649147ebba8a2dda09dd4d97dc3c1d830925)

-Si ocurrió en una arista, sea el nodo creado para partir dicha arista, sea el padre y sea la etiqueta de la arista . La extensión se realiza de forma análoga al caso anterior.
Obsérvese que la extensión no puede ocurrir en la raíz pues esta no es la última extensión de la fase.
Skip/count trick[editar]
Cuando se desea buscar la localización del final de una cadena en el árbol y se tiene la certeza de que esta se encuentra (como es el caso de las búsquedas que se realizan en las extensiones), no es necesario machear la cadena carácter a carácter, en estos casos es posible utilizar el skip/count trick que permite realizar la búsqueda en un orden linear respecto al número de nodos del camino.
Sea el nodo en el que se encuentra el algoritmo, intentando localizar la cadena , el skip/count trick ejecuta sucesivamente el siguiente procedimiento hasta obtener la posición buscada:

Si S es la cadena vacía, cur es la posición buscada.
Sino (cur,v) es la arista etiqueta L comparte el primer carácter con S (tiene que existir y ser única)
Si |L|<|S|, la posición buscada es el carácter |S|-ésimo de la arista (cur,v).
Sino hacer cur=v y eliminar los primeros |L| caracteres de S
Lema: Sea un suffix link atravesado durante el algoritmo de Ukkonen. En ese momento está acotada por .


Demostración: Cuando el link (es atravesado, todo nodo interno ancestro de , con etiqueta (donde es un carácter y una cadena posiblemente vacía) tiene un suffix link hacia un nodo , etiquetado con , ancestro de . Esta correspondencia es además unívoca. El único ancestro que puede tener sin su correspondiente ancestro para es la raíz.

Teorema: Usando el skip/count trick, toda fase del algoritmo de Ukkonen toma un tiempo donde .

Demostración: hay extensiones en la fase , en una extensión el algoritmo sube en el árbol a lo sumo un nodo, atraviesa a lo sumo un suffix link, baja en el árbol cierto número de nodos, aplica la extensión y añada a lo sumo un suffix link. Todas las operaciones distintas del descenso en el árbol toman tiempo constante. Solo necesitamos analizar la suma de los tiempos de realizar los descensos de todas las extensiones en la fase.

Para ello nos centraremos en la profundidad del nodo donde el algoritmo termina la fase. Al inicio de la fase se parte de la raíz, que tiene profundidad , como , en la fase se realizan a lo sumo descensos de profundidad (cuando se sube al padre o se atraviesa un suffix link), pero la profundidad del está acotada por , por tanto el número de aumentos de profundidad está acotado por ya que , y como cada descenso en el árbol aumenta la profundidad, el número de descensos en toda la fase está acotado por . Por tanto el tiempo que toma realizar una fase es .




Corolario: El algoritmo de Ukkonen puede ser implementado usando suffix links en tiempo .

Extensiones implícitas[editar]
Observación: Una vez que la regla 3 aplica en la extensión de la fase , la regla 3 aplicará en el resto de las extensiones de la fase .
Esto es debido a que cuando la regla 3 aplica, es porque la cadena pertenece al árbol antes de realizar la extensión y por tanto las cadenas también pertenecen al árbol, por tanto en las extensiones , la regla 3 también aplicará.
![{\displaystyle S[j+1..i],...,S[i..i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/581a18ffdd4a1e4d373f828d72c49d2664675959)

Observación: La extensión crea un suffix link solo cuando en la extensión aplica la regla 2.
Stop Trick[editar]
Es posible terminar la fase la primera vez que la regla 3 aplique. Si esto ocurre en la extensión , se dice que las extensiones se realizaron de forma implícita.

Observación: Sea la primera extensión de la fase en la que la regla 3 aplica, se cumple que las primeras extensiones de la fase solo pudieron aplicar las reglas 1 o 2. Ambas reglas determinan una hoja etiquetada con el sufijo de que se extendió. En la fase las primeras extensiones ocurrirán en las hojas determinadas por las primeras j'-1 extensiones de la fase i. Por tanto en las primeras extensiones de la fase aplicará la regla 1.


Observación: Cuando la regla 1 aplica en la fase , en una hoja , se sustituye la etiqueta de la arista incidente en la hoja por . Esto da lugar a la siguiente mejora.
![{\displaystyle [p,i]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5c6891cbc296f92e664fc884b42933cab308b4f2)
![{\displaystyle [p,i+1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/71a6709bfda239f051226ae26328eeaeec579f48)
Pointer Trick[editar]
Cada vez que una hoja es creada en la fase , se etiqueta la arista incidente a dicha hoja con el par , el pointer trick propone etiquetar dicha arista con el par , donde es un puntero al número que identifica la fase actual. De esta forma no es necesario hacer nada cuando aplica la regla 1. Como se tiene que las primeras en las primeras extensiones de la fase aplicará la regla 1, es posible comenzar la fase a partir de la extensión , dejando que las primeras extensiones, se realicen de forma implícita.
![{\displaystyle [p,e]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2960d102d1afc1608b520b846ce83838837e81e6)

Teorema: El algoritmo de Ukkonen construye el árbol de sufijos de , con los suffix links con costo espacial y temporal .
Demostración: El tiempo para realizar todas las extensiones implícitas a lo largo del algoritmo es constante.
Consideremos el índice correspondiente a la extensión explicita actual, en toda la ejecución del algoritmo de Ukkonen nunca decrece, aunque sí se mantiene invariante cuando pasa de una fase a la siguiente. Como solo hay fases, el número de extensiones explícitas está acotado por . El algoritmo por tanto ejecuta a lo sumo extensiones explícitas.
Como se explicó anteriormente el costo temporal de una extensión explícita depende del costo temporal de realizar el descenso en el árbol en dicha extensión. Para acotar el número de nodos recorridos en los descensos en el árbol durante el algoritmo de Ukkonen, es importante observar, que el nodo actual no varía cuando el algoritmo cambia de fase, la acotación se efectúa de forma análoga a como se hizo en la demostración del teorema anterior.
algoritmo de Viterbi es un algoritmo de programación dinámica que permite hallar la secuencia más probable de estados ocultos (el llamado camino de Viterbi) que produce una secuencia observada de sucesos, especialmente en el contexto de fuentes de información de Márkov y modelos ocultos de Márkov.
Se aplica de forma general en la descodificación de códigos convolucionales usados en redes de telefonía celular digital GSM y CDMA, módems de líneas conmutadas, satélites, comunicaciones espaciales y redes inalámbricas IEEE 802.11. También se usa en reconocimiento del habla, síntesis de habla, diarización, búsqueda de palabras clave, lingüística computacional y bioinformática.
Introducción[editar]
El algoritmo de Viterbi permite encontrar las secuencias de estados más probable en un Modelo oculto de Márkov(MOM), , a partir de una observación , es decir, obtiene la secuencia óptima que mejor explica la secuencia de observaciones.


Consideremos la variable que se define como:


es la probabilidad del mejor camino hasta el estado habiendo visto las primeras observaciones. Esta función se calcula para todos los estados e instantes de tiempo.

![{\displaystyle \delta _{t+1}{(j)}={\biggl [}\max _{1\leq i\leq N}{\delta _{t}{(i)(a_{ij})}}{\biggr ]}b_{j}(o_{t+1})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/93b2b8d6c56ebc247b475020a7d4b158b0429be5)
Puesto que el objetivo es obtener las secuencia de estados más probable, será necesario almacenar el argumento que hace máxima la ecuación anterior en cada instante de tiempo y para cada estado y para ello utilizamos la variable .

A continuación se detalla el proceso completo utilizando las funciones y .


Algoritmo[editar]
Inicialización[editar]

donde

Recursión[editar]
,
![{\displaystyle \delta _{t+1}{(j)}={\biggl [}\max _{1\leq i\leq N}{\delta _{t}{(i)}a_{ij}}{\biggr ]}b_{j}(o_{t+1})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ca0926dbc65c8be0eefe97969b1d273cb433ea45)
donde:
,


,

donde:
,
Terminación[editar]

Reconstrucción de la secuencia de estados más probable[editar]
,

donde:

Algunos de los cálculos del algoritmo de Viterbi recuerdan a los del algoritmo forward necesario para calcular eficientemente la probabilidad de una secuencia de observables. Una de las diferencias es la incorporación de la función (en lugar de sumar las probabilidades) para calcular la secuencia de estados más probable.

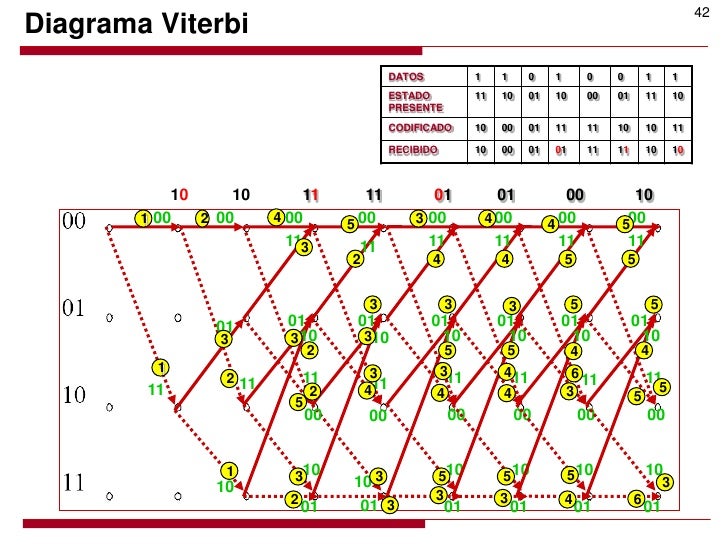
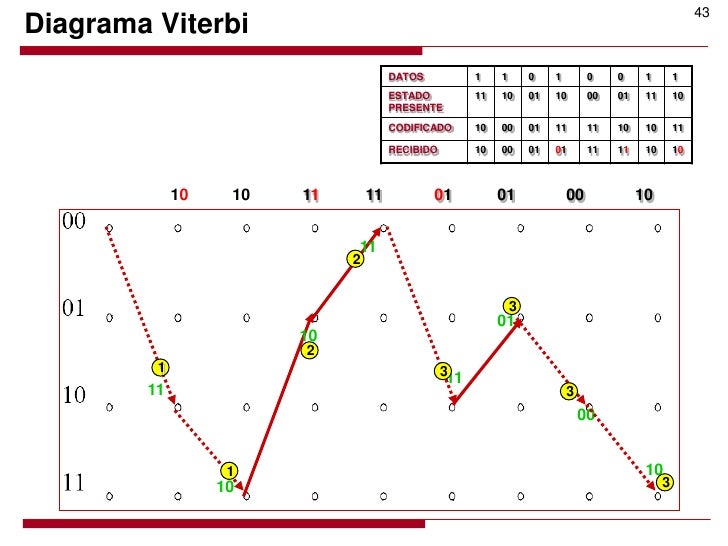
Ejemplo de secuencia de estados más probable
La figura muestra un ejemplo de secuencia de estados más probable en un Modelo Oculto de Márkov de 5 estados dada una secuencia de observaciones de longitud 5.

Aplicación del algoritmo de Viterbi[editar]
Muy usado para reconocimiento de voz, biología molecular, fonemas, palabras, codificadores entre otros. A cada secuencia de estados le corresponde una secuencia de etiquetas (o labels) de clasificación, es decir, palabras, caracteres, fonemas, sufijos. Dada una secuencia observada, se deduce la más probable secuencia de estados.
Desambiguación léxica categorial[editar]
Una de las aplicaciones del algoritmo de Viterbi es en el área de procesamiento del lenguaje natural, más concretamente en el proceso de desambiguación léxica categorial.
En este caso particular, los elementos de un Modelo Oculto de Márkov serían los siguientes:
- El conjunto de estados sería el conjunto de posibles etiquetas (categorías gramaticales) para las palabras.
- El conjunto de observables en cada uno de los estados corresponde con el conjunto de palabras distintas.
- El conjunto de probabilidades de transiciones entre estados sería la probabilidad de que una determinada categoría categorial siga a otra. Por ejemplo, la probabilidad de que la categoría nombre vaya detrás de la categoría determinante.
- El conjunto de probabilidades de las observaciones correspondería con la probabilidad de pertenencia de una palabra (un observable) a una determinada categoría. Por ejemplo, la probabilidad de que la palabra casa sea verbo, que será menor que la probabilidad de que esta misma palabra tenga la categoría gramatical nombre.




La figura siguiente muestra un ejemplo de etiquetado gramatical para la oración "Coto privado de caza"

En él, los observables son la secuencia de palabras de la oración. Se puede observar como para cada palabra se contempla sólo un conjunto limitado de posibles categorías gramaticales (caza puede ser o nombre o verbo). Este es debido a que la probabilidad de pertenencia de determinadas palabras a una categoría gramatical es nula (como la probabilidad de que la palabra caza sea adverbio). Esto simplifica enormemente los cálculos en el modelo.
Otras preguntas fundamentales[editar]
Otros dos problemas que es importante saber resolver para utilizar los MOM son:
- ¿Cuál es la probabilidad de una secuencia de observaciones dado un modelo ? Es decir, ¿cómo podemos calcular de forma eficiente ?. Para esto se puede usar el algoritmo de avance-retroceso.
- Dada una secuencia de observaciones , ¿cómo podemos estimar los parámetros del modelo para maximizar . En este caso el objetivo es encontrar el modelo que mejor explica la secuencia observada. Para esto se puede usar el algoritmo de Baum-Welch.


El algoritmo de Viterbi encuentra las secuencias de estados más probables a partir de una observación al modelo oculto de Markov, es decir, se obtiene la secuencia óptima que explica la secuencia observada [6]. Las características utilizadas para el decodificador Viterbi permiten una corrección de hasta 4 bits erróneos. Para este sistema se realiza una descripción de la técnica de doble buffer [5], ya que la decodificación empieza a partir del último bit, necesitando así de una memoria en la salida que permita retornar los bits en el orden correcto, en la figura 7 se puede observar la conexión completa del decodificador.
Diagrama del codificador Convolucional. 2) Decodificador de Viterbi El algoritmo de Viterbi encuentra las secuencias de estados más probables a partir de una observación al modelo oculto de Markov, es decir, se obtiene la secuencia óptima que explica la secuencia observada [6]. Las características utilizadas para el decodificador Viterbi permiten una corrección de hasta 4 bits erróneos. Para este sistema se realiza una descripción de la técnica de doble buffer [5], ya que la decodificación empieza a partir del último bit, necesitando así de una memoria en la salida que permita retornar los bits en el orden correcto, en la figura 7 se puede observar la conexión completa del decodificador.
No hay comentarios:
Publicar un comentario