Ecuaciones
La ecuación de Bellman, también conocida como la ecuación de programación dinámica, nombrada en honor de su descubridor, Richard Bellman, es una condición necesaria para la optimalidad asociada con el método de la optimización matemática conocida como programación dinámica. Se escribe el valor de un problema de decisión en un determinado punto en el tiempo en términos de la recompensa que dan algunas opciones iniciales y el valor del problema de decisión restante que resulta de esas opciones iniciales. Esto rompe un problema de optimización dinámica en subproblemas más simples, tal como el Principio de optimalidad de Bellman establece.
La ecuación de Bellman se aplicó primero a la ingeniería en la teoría de control y otros temas de matemática aplicada y, posteriormente, se convirtió en una herramienta importante en la teoría económica.
Casi cualquier problema que puede ser resuelto usando la teoría de control óptimo también se puede resolver mediante el análisis de la ecuación de Bellman apropiada. Sin embargo, el término "ecuación de Bellman" por lo general se refiere a la ecuación de programación dinámica asociada a tiempo discreto problemas de optimización. En los problemas de optimización en tiempo continuo, la ecuación análoga es una ecuación diferencial parcial que generalmente se llama la ecuación de Hamilton-Jacobi-Bellman.
Conceptos analíticos en programación dinámica
Para entender la ecuación de Bellman, varios conceptos subyacentes deben ser entendidos. En primer lugar, cualquier problema de optimización debe tener un objetivo - reducir al mínimo el tiempo de viaje, reduciendo al mínimo coste, maximizar los beneficios, maximización de la utilidad, etcétera. La función matemática que describe este objetivo se denomina función objetivo.
La programación dinámica descompone un problema de planificación de múltiples períodos en pasos más simples para diferentes momentos. Por lo tanto, se requiere hacer el seguimiento de cómo la situación de decisión está evolucionando en el tiempo. La información sobre la situación actual que se necesita para tomar una decisión correcta se llama el estado (Ver Bellman, 1957, cap. III.2).1 2 Por ejemplo, para decidir cuánto consumir y gastar en cada punto en el tiempo, la gente tendría que saber (entre otras cosas) su riqueza inicial. Por lo tanto, la riqueza sería una de sus variables de estado, pero probablemente habría otras.
Las variables seleccionadas en cualquier punto dado en el tiempo se llaman variables de control. Por ejemplo, dada su riqueza actual, la gente podría decidir cuánto consumir ahora. La elección de las variables de control ahora puede ser equivalente a la elección de la siguiente estado; más en general, el siguiente estado se ve afectada por otros factores, además de la regulación de corriente. Por ejemplo, en el caso más sencillo, la riqueza de hoy (el estado) y el consumo (el control) pueden determinar con exactitud la riqueza de mañana (el nuevo estado), aunque por lo general otros factores pueden afectar la riqueza de mañana también.
El enfoque de programación dinámica describe el plan óptimo mediante la búsqueda de una regla que dice lo que los controles deben ser, teniendo en cuenta cualquier posible valor del estado. Por ejemplo, si el consumo (c) solo depende de la riqueza (W), entonces se buscaría una regla  que da el consumo en función de la riqueza. Tal regla general, la determinación de los controles como una función de los estados, se llama una función de política (Ver Bellman, 1957, cap. III.2).1
que da el consumo en función de la riqueza. Tal regla general, la determinación de los controles como una función de los estados, se llama una función de política (Ver Bellman, 1957, cap. III.2).1
que da el consumo en función de la riqueza. Tal regla general, la determinación de los controles como una función de los estados, se llama una función de política (Ver Bellman, 1957, cap. III.2).1
Por último, por definición, la regla de decisión óptima es la que logra el mejor valor posible del objetivo. Por ejemplo, si alguien elige el consumo, la riqueza dada, con el fin de maximizar la felicidad (suponiendo que la felicidad H puede ser representado por una función matemática, tal como una utilidad de función), a continuación, cada nivel de la riqueza se asocia con algún nivel más alto posible de la felicidad , . El mejor valor posible del objetivo, escrita como una función del estado, se llama la función de valor.
. El mejor valor posible del objetivo, escrita como una función del estado, se llama la función de valor.
. El mejor valor posible del objetivo, escrita como una función del estado, se llama la función de valor.
Richard Bellman mostró que una dinámica de optimización de un problema en tiempo discreto se puede afirmar en un recursivo forma, paso a paso, anotando la relación entre la función de valor en un período y el valor de la función en el próximo período. La relación entre estas dos funciones de valor se llama la ecuación de Bellman.
Derivación de la ecuación de Bellman
Un problema de decisión dinámico
Sea 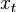 el estado en el momento
el estado en el momento  . Para una decisión que comienza en el momento 0, tomamos como dado el estado inicial
. Para una decisión que comienza en el momento 0, tomamos como dado el estado inicial 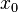 . En cualquier momento, el conjunto de posibles acciones depende del estado actual; podemos escribir esto como
. En cualquier momento, el conjunto de posibles acciones depende del estado actual; podemos escribir esto como  , Donde la acción a_t representa una o más variables de control. También suponemos que el estado cambia de x a un nuevo estado T (x, a) cuando la acción a se toma, y que el pago actual de la adopción de medidas un en el estado de x es F (x, a) . Por último, asumimos la impaciencia, representado por un factor de descuento 0 <\ beta <1 .="" p="">
, Donde la acción a_t representa una o más variables de control. También suponemos que el estado cambia de x a un nuevo estado T (x, a) cuando la acción a se toma, y que el pago actual de la adopción de medidas un en el estado de x es F (x, a) . Por último, asumimos la impaciencia, representado por un factor de descuento 0 <\ beta <1 .="" p="">
el estado en el momento . Para una decisión que comienza en el momento 0, tomamos como dado el estado inicial . En cualquier momento, el conjunto de posibles acciones depende del estado actual; podemos escribir esto como , Donde la acción a_t representa una o más variables de control. También suponemos que el estado cambia de x a un nuevo estado T (x, a) cuando la acción a se toma, y que el pago actual de la adopción de medidas un en el estado de x es F (x, a) . Por último, asumimos la impaciencia, representado por un factor de descuento 0 <\ beta <1 .="" p="">
Bajo estos supuestos, un problema de horizonte infinito decisión toma la siguiente forma:

sujeto a las limitaciones:

Nótese que se ha definido la notación V (x 0) para representar el valor óptimo que se puede obtener mediante la maximización de la función objetivo con sujeción a las limitaciones asumidas. Esta función es la función de valor. Es una función de la variable de estado inicial x 0, ya que la mejor relación puede obtener depende de la situación inicial.
Principio de Bellman de optimalidad
El método de programación dinámica rompe este problema de decisión en subproblemas más pequeños. Principio de Richard Bellman de optimalidad se explica cómo hacerlo:
Principio de optimalidad: Una política óptima tiene la propiedad de que cualquiera que sea el estado inicial y la decisión inicial son, las decisiones restantes deben constituir una política óptima en relación con el estado resultante de la primera decisión. (Ver Bellman, 1957, Cap. III.3). [1] [2] [3]
En informática, se dice que un problema que puede ser descompuesto como este para tener subestructura óptima . En el contexto de la dinámica de la teoría de juegos , este principio es análogo al concepto de equilibrio perfecto en subjuegos , a pesar de lo que constituye una política óptima en este caso, está condicionado a los opositores del decisor elegir políticas igualmente óptimos de sus puntos de vista.
Como sugiere el principio de optimalidad, consideraremos la primera decisión por separado, dejando de lado todas las decisiones futuras (vamos a empezar de nuevo de vez en 1 con el nuevo estado  ). La recogida de las futuras decisiones entre paréntesis a la derecha, el problema anterior es equivalente a:
). La recogida de las futuras decisiones entre paréntesis a la derecha, el problema anterior es equivalente a:
). La recogida de las futuras decisiones entre paréntesis a la derecha, el problema anterior es equivalente a:![\max_{ a_0 } \left \{ F(x_0,a_0)
+ \beta \left[ \max_{ \left \{ a_{t} \right \}_{t=1}^{\infty} }
\sum_{t=1}^{\infty} \beta^{t-1} F(x_t,a_{t}) \; \; s.t. \; \;
a_{t} \in \Gamma (x_t), \; x_{t+1}=T(x_t,a_t), \; \forall t = 1, 2, \dots \right] \right \}](https://upload.wikimedia.org/math/6/5/e/65e59be1f59506ccb13fdfeb8b67cc54.png)
sujeto a las restricciones:
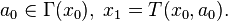
Aquí estamos eligiendo 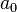 , Sabiendo que nuestra elección hará que el tiempo de 1 estado sea
, Sabiendo que nuestra elección hará que el tiempo de 1 estado sea  . Ese nuevo estado será entonces afectar el problema de decisión de vez en 1. Todo el problema de decisión futura aparece dentro de los corchetes de la derecha.
. Ese nuevo estado será entonces afectar el problema de decisión de vez en 1. Todo el problema de decisión futura aparece dentro de los corchetes de la derecha.
, Sabiendo que nuestra elección hará que el tiempo de 1 estado sea . Ese nuevo estado será entonces afectar el problema de decisión de vez en 1. Todo el problema de decisión futura aparece dentro de los corchetes de la derecha.Ecuación de Bellman
De momento parece que solo hemos hecho el problema más complicado al separar la decisión de hoy de las decisiones futuras. Pero podemos simplificar por darse cuenta de que lo que está dentro de los corchetes de la derecha es el valor del tiempo de problema de decisión 1, a partir de un estado .
.
Por lo tanto se puede reescribir el problema como un recurrente definición de la función de valor:
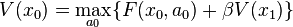
sujeto a la restricción:
Esta es la ecuación de Bellman. Se puede simplificar aún más si se cae subíndices de tiempo y el enchufe en el valor del siguiente estado:

La ecuación de Bellman se clasifica como una ecuación funcional , porque resolver que significa la búsqueda de la función desconocida V, que es la función de valor. Recordemos que la función de valor describe el mejor valor posible del objetivo, como una función del estado x. Mediante el cálculo de la función de valor, también se encuentra la función a (x) que describe la acción óptima en función de la situación, lo que se llama a la función política.
La ecuación de Bellman en un problema estocástico
En el ajuste determinista, además de otras técnicas de programación dinámica pueden utilizarse para hacer frente a lo anterior control óptimo problema. Aunque el agente tiene que dar cuenta de la estocasticidad, este enfoque se vuelve conveniente para ciertos problemas.
Para un ejemplo específico de la economía, considere un consumidor infinitamente duración con una dotación inicial de riqueza en el periodo 0. Él tiene una instantánea función de utilidad U (c) donde c denota el consumo y descuenta el siguiente utilidad periodo a una tasa de 0 <β <1 .="" c="" con="" consume="" consumidor="" consumo="" de="" del="" el="" elegir="" en="" es="" inter="" lo="" luego="" maximizaci="" n="" no="" odo="" p="" per="" plan="" pr="" problema="" que="" r.="" resuelve:="" s="" se="" supongamos="" t="" tasa="" traslada="" un="" utilidad="" ximo="">
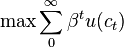
sujeto a:

y
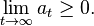
La primera restricción es la acumulación de capital / ley de movimiento especificado por el problema, mientras que la segunda restricción es una condición de transversalidad que el consumidor no realiza la deuda al final de su vida. La ecuación de Bellman es

Como alternativa, se puede tratar el problema directamente con la secuencia, por ejemplo, los hamiltonianos ecuaciones.
Ahora, si la tasa de interés varía de un período a otro, el consumidor es la cara con un problema de optimización estocástica. Que el interés r sigue un proceso de Markov con función de probabilidad de transición Q (r, dμ r) donde dμ r denota la medida de probabilidad que rige la distribución del próximo periodo de tipos de interés si la tasa de interés actual es r. El calendario de este modelo es que el consumidor decide su consumo actual periodo después de que se anunció la tasa de interés actual período.
En lugar de simplemente eligiendo una única secuencia {c} t, el consumidor debe ahora elegir una secuencia {c} t para cada posible realización de un r {t} de tal manera que su utilidad esperada vida útil se maximiza:

La expectativa E se toma con respecto a la medida de probabilidad apropiada dada por Q en las secuencias de r 's. Debido a que r es gobernado por un proceso de Markov, programación dinámica simplifica el problema de manera significativa. A continuación, la ecuación Bellman es simplemente

Bajo algunas hipótesis razonable, la función política óptima g resultante (a, r) es medible.
Para un problema de optimización estocástica secuencial general choques Markov y donde el agente se enfrenta a la decisión ex-post , la ecuación de Bellman toma una forma muy similar

Métodos de solución
El método de coeficientes indeterminados , también conocido como "adivinar y verificar", se puede utilizar para resolver algunos de horizonte infinito, autónomas ecuaciones de Bellman.
La ecuación de Bellman puede ser resuelta por inducción hacia atrás , ya sea analíticamente en unos pocos casos especiales, o numéricamente en un ordenador. La inducción hacia atrás numérica es aplicable a una amplia variedad de problemas, pero puede ser no factible cuando hay muchas variables de estado, debido a la maldición de la dimensionalidad. Programación aproximado dinámica ha sido introducido por DP Bertsekas y JN Tsitsiklis con el uso de redes neuronales artificiales ( perceptrones multicapa ) para la aproximación de la función de Bellman. [4] Esta es una estrategia de mitigación eficaz para reducir el impacto de la dimensionalidad mediante la sustitución de la memorización de la correlación de funciones completo para el dominio de todo el espacio con la memorización de los únicos parámetros de la red neural.
Mediante el cálculo de las condiciones de primer orden asociados con la ecuación de Bellman y, a continuación, utilizando el teorema de la envolvente para eliminar los derivados de la función de valor, es posible obtener un sistema de ecuaciones en diferencias o ecuaciones diferenciales llamados los " ecuaciones de Euler . Las técnicas estándar para la solución de la diferencia o ecuaciones diferenciales pueden usarse entonces para calcular la dinámica de las variables de estado y las variables de control del problema de optimización.
Aplicaciones en economía
El primer uso conocido de una ecuación de Bellman en la economía se debe a Martin Beckmann y Richard Muth.3 Martin Beckmann también escribió extensamente sobre la teoría del consumo mediante la ecuación de Bellman en 1959. Su obra influyó Edmund S. Phelps, entre otros.
Una aplicación económica celebrado de una ecuación de Bellman es seminal artículo de Merton 1973 en el Capital Asset Pricing Model intertemporal.4 (Véase también el problema de la cartera de Merton ). La solución al modelo teórico de Merton, uno en el que los inversores optaron entre el ingreso actual y el ingreso futuro o ganancias de capital, es una forma de la ecuación de Bellman. Dado que las aplicaciones económicas de programación dinámica suelen dar lugar a una ecuación de Bellman que es una ecuación en diferencias, los economistas se refieren a la programación dinámica como un "método recursivo" y un subcampo de la economía recursivas es ahora reconocido en Economía.
No hay comentarios:
Publicar un comentario