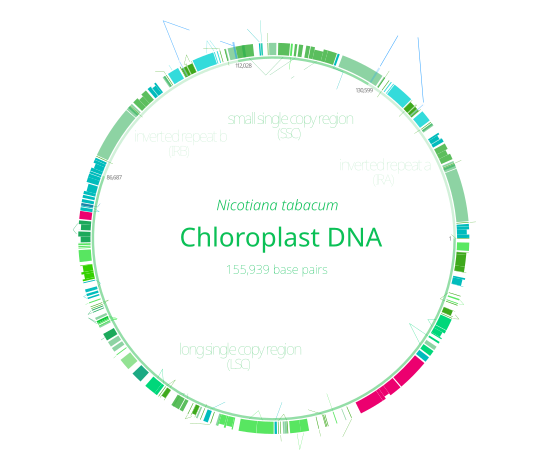
ADN del cloroplasto Mapa genético interactivo del ADN del cloroplasto de Nicotiana tabacum . Los segmentos con etiquetas en el interior residen en la cadena B del ADN , los segmentos con etiquetas en el exterior están en la cadena A. Las muescas indican intrones .
Los cloroplastos tienen su propio ADN , [1] [2] a menudo abreviado como cpDNA . [3] También se conoce como el plastomacuando se refiere a genomas de otros plastos . Su existencia se probó por primera vez en 1962 [4] y se secuenció por primera vez en 1986, cuando dos equipos de investigación japoneses secuenciaron el ADN de cloroplasto de hepática y tabaco . [5] Desde entonces, cientos de ADN de cloroplastos de varias especies han sido secuenciados , pero en su mayoría son de plantas terrestres y algas verdes .Los glaucofitos , las algas rojas y otros grupos de algas están muy poco representados, lo que potencialmente introduce cierto sesgo en las vistas de la estructura y el contenido del ADN del cloroplasto "típico".
Estructura molecular [ editar ]

Los ADN de los cloroplastos son circulares y suelen tener una longitud de 120,000–170,000 pares de bases . [4] [7] [8] Pueden tener una longitud de contorno de alrededor de 30 a 60 micrómetros y una masa de alrededor de 80 a 130 millones de daltons . [9]
La mayoría de los cloroplastos tienen todo su genoma de cloroplasto combinado en un solo anillo grande, aunque los de dinophyte algas son una notable excepción: su genoma se divide en unos cuarenta plásmidos pequeños , cada uno de 2,000–10,000 pares de bases de largo. [6] Cada minicírculo contiene uno a tres genes, [6] [10]pero también se han encontrado plásmidos en blanco, sin ADN codificante .
Repeticiones invertidas [ editar ]
Muchos ADN de cloroplastos contienen dos repeticiones invertidas , que separan una sección de copia única larga (LSC) de una sección de copia única corta (SSC). [8]
Las repeticiones invertidas varían enormemente en longitud, con un rango de 4,000 a 25,000 pares de basescada una. [6] Las repeticiones invertidas en las plantas tienden a estar en el extremo superior de este rango, cada una de 20,000 a 25,000 pares de bases. [8] [11] Las regiones de repetición invertida generalmente contienen tres ARN ribosomal y dos genes de ARNt , pero pueden expandirse o reducirse para contener tan solo cuatro o tantos como más de 150 genes. [6] Si bien un par dado de repeticiones invertidas rara vez son completamente idénticas, siempre son muy similares entre sí, aparentemente como resultado de una evolución concertada . [6]
Las regiones repetidas invertidas están altamente conservadas entre las plantas terrestres y acumulan pocas mutaciones. [8] [11] Repeticiones invertidas similares existen en los genomas de las cianobacterias y en las otras dos líneas de cloroplastos ( glaucophyta y rhodophyceæ ), lo que sugiere que son anteriores al cloroplasto, [6]aunque algunos ADN de cloroplastos como los de los guisantes y algunas algas rojas [6] Desde entonces han perdido las repeticiones invertidas. [11] [12] Otros, como el alga roja Porphyra volcó una de sus repeticiones invertidas (haciéndolas repeticiones directas). [6]Es posible que las repeticiones invertidas ayuden a estabilizar el resto del genoma del cloroplasto, ya que los ADN de cloroplastos que han perdido algunos de los segmentos de repetición invertida tienden a reorganizarse más. [12]
Estructura lineal [ editar ]
Durante mucho tiempo se pensó que el ADN del cloroplasto tenía una estructura circular, pero algunas evidencias sugieren que el ADN del cloroplasto generalmente toma una forma lineal. [13] Se ha observado que más del 95% del ADN del cloroplasto en los cloroplastos de maíz se encuentra en forma lineal ramificada en lugar de círculos individuales. [6]
Nucleoides [ editar ]
Cada cloroplasto contiene alrededor de 100 copias de su ADN en hojas jóvenes, disminuyendo a 15-20 copias en hojas más viejas. [14] Por lo general, están empacados en nucleósidos que pueden contener varios anillos de ADN de cloroplasto idénticos. En cada cloroplasto se pueden encontrar muchos nucleoides. [9]
Aunque el ADN del cloroplasto no está asociado con histonas verdaderas , [15] en algas rojas , se ha encontrado una proteína de cloroplasto (HC) similar a la histona codificada por el ADN del cloroplasto que empaqueta cada anillo de ADN de cloroplasto en un nucleoide . [dieciséis]
En las algas rojas primitivas , los nucleósidos del ADN del cloroplasto se agrupan en el centro de un cloroplasto, mientras que en las plantas verdes y las algas verdes , los nucleoides se dispersan por todo el estroma . [dieciséis]
La replicación del ADN [ editar ]
Modelo líder de replicación de cpDNA [ editar ]

El mecanismo para la replicación del ADN del cloroplasto (ADNcp) no se ha determinado de manera concluyente, pero se han propuesto dos modelos principales. Los científicos han intentado observar la replicación del cloroplasto a través de microscopía electrónica desde la década de 1970. [17] [18] Los resultados de los experimentos de microscopía llevaron a la idea de que el ADN del cloroplasto se replica utilizando un bucle de doble desplazamiento (bucle D). A medida que el bucle D se mueve a través del ADN circular, adopta una forma intermedia theta, también conocida como un intermediario de replicación de Cairns, y completa la replicación con un mecanismo de círculo rodante. [17] [19] La replicación comienza en puntos específicos de origen. Horquillas de replicación múltipleabrir, permitiendo que la maquinaria de replicación replique el ADN. A medida que continúa la replicación, las horquillas crecen y eventualmente convergen. Las nuevas estructuras de cpDNA se separan, creando cromosomas hijas de cpDNA.
Además de los primeros experimentos de microscopía, este modelo también está respaldado por las cantidades de desaminación observadas en cpDNA. [17] La desaminación ocurre cuando se pierde un grupo amino y es una mutación que a menudo produce cambios en la base. Cuando la adenina se desamina, se convierte en hipoxantina . La hipoxantina se puede unir a la citosina , y cuando el par de bases XC se replica, se convierte en un GC (por lo tanto, un cambio de base A → G). [20]

En cpDNA, hay varios gradientes de desaminación A → G. El ADN se vuelve susceptible a los eventos de desaminación cuando es monocatenario. Cuando se forman las horquillas de replicación, la hebra que no se copia es de una sola hebra y, por lo tanto, está en riesgo de desaminación A → G. Por lo tanto, los gradientes en la desaminación indican que las horquillas de replicación estaban más probablemente presentes y la dirección en la que se abrieron inicialmente (el gradiente más alto es más probable que esté más cerca del sitio de inicio debido a que fue de una sola hebra por el mayor tiempo). [17]Este mecanismo sigue siendo la teoría principal hoy en día; sin embargo, una segunda teoría sugiere que la mayoría de los ADNcp es en realidad lineal y se replica a través de una recombinación homóloga. Además, sostiene que solo una minoría del material genético se mantiene en cromosomas circulares, mientras que el resto está en estructuras ramificadas, lineales u otras complejas. [17] [19]
Modelo alternativo de replicación [ editar ]
Uno de los principales modelos de la competencia para cpDNA afirma que la mayoría del cpDNA es lineal y participa en la recombinación homóloga y en las estructuras de replicación similares al bacteriófago T4 . [19] Se ha establecido que algunas plantas tienen cpDNA lineal, como el maíz, y que aún más contienen estructuras complejas que los científicos aún no comprenden; [19] sin embargo, la opinión predominante hoy en día es que la mayoría de los cpDNA son circulares. Cuando se realizaron los experimentos originales en cpDNA, los científicos notaron estructuras lineales; sin embargo, atribuyeron estas formas lineales a círculos rotos. [19]Si las estructuras ramificadas y complejas que se ven en los experimentos con ADNcp son reales y no son artefactos de ADN circular concatenado o círculos rotos, entonces el mecanismo de replicación del bucle D es insuficiente para explicar cómo se replicarían esas estructuras. [19] Al mismo tiempo, la recombinación homóloga no explica los múltiples gradientes A → G observados en los plastomas. [17] Este defecto es uno de los más grandes para la teoría de la estructura lineal.
Gene contenido y la síntesis de proteínas [ editar ]
El genoma del cloroplasto incluye más comúnmente alrededor de 100 genes [7] [10] que codifican una variedad de cosas, principalmente relacionadas con la línea de proteínas y la fotosíntesis . Como en los procariotas , los genes en el ADN del cloroplasto se organizan en operones . [10] Los intrones son comunes en las moléculas de ADN del cloroplasto, mientras que son raros en las moléculas de ADN procarióticas ( los ADN mitocondriales de las plantas suelen tener intrones, pero no el ADNmt humano). [21]
Entre las plantas terrestres, el contenido del genoma del cloroplasto es bastante similar [8]: codifican cuatro ARN ribosómicos , 30–31 ARNt , 21 proteínas ribosómicas y cuatro subunidades de ARN polimerasa , [22] [23]involucradas en la síntesis de proteínas. Para la fotosíntesis, el ADN del cloroplasto incluye genes para 28 proteínas tilacoides y la gran subunidad Rubisco . [22] Además, sus genes codifican once subunidades de un complejo proteico que media las reacciones redox para reciclar electrones, [24] que es similar a la NADH deshidrogenasaencontrado en las mitocondrias. [22] [25]
Reducción del cloroplasto del genoma y la transferencia de genes [ editar ]
Con el tiempo, muchas partes del genoma del cloroplasto se transfirieron al genoma nuclear del huésped, [4] [7] [26] un proceso llamado transferencia de genes endosimbióticos . Como resultado, el genoma del cloroplasto está muy reducido en comparación con el de las cianobacterias de vida libre. Los cloroplastos pueden contener entre 60 y 100 genes, mientras que las cianobacterias suelen tener más de 1500 genes en su genoma. [27] Por el contrario, solo hay unos pocos casos conocidos en los que los genes se han transferido al cloroplasto de varios donantes, incluidas las bacterias. [28] [29] [30]
La transferencia de genes endosbióticos es cómo sabemos acerca de los cloroplastos perdidos en muchos linajes de cromalveolatos . Incluso si un cloroplasto se pierde finalmente, los genes que donó al núcleo del huésped anterior persisten, lo que proporciona evidencia de la existencia del cloroplasto perdido. Por ejemplo, mientras que las diatomeas (un heterocontofito ) ahora tienen un cloroplasto derivado de algas rojas , la presencia de muchos genes de algas verdes en el núcleo de diatomeas proporciona evidencia de que el ancestro de diatomeas (probablemente el antecesor de todos los cromalveolatos también) tenía un cloroplasto derivado de algas verdes en Algún punto, que posteriormente fue sustituido por el cloroplasto rojo. [31]
En las plantas terrestres, entre el 11 y el 14% del ADN en sus núcleos se remonta al cloroplasto, [32] hasta el 18% en Arabidopsis , que corresponde a unos 4.500 genes codificantes de proteínas. [33] Ha habido algunas transferencias recientes de genes del ADN del cloroplasto al genoma nuclear en plantas terrestres. [7]
Proteínas codificadas por el cloroplasto [ editar ]
De las aproximadamente tres mil proteínas encontradas en los cloroplastos, alrededor del 95% de ellas están codificadas por genes nucleares. Muchos de los complejos de proteínas del cloroplasto consisten en subunidades del genoma del cloroplasto y del genoma nuclear del huésped. Como resultado, la síntesis de proteínas debe coordinarse entre el cloroplasto y el núcleo. El cloroplasto se encuentra principalmente bajo control nuclear, aunque los cloroplastos también pueden emitir señales que regulan la expresión génica en el núcleo, lo que se denomina señalización retrógrada . [34]
Síntesis de proteínas [ editar ]
La síntesis de proteínas dentro de los cloroplastos se basa en una ARN polimerasa codificada por el propio genoma del cloroplasto, que se relaciona con las ARN polimerasas que se encuentran en las bacterias. Los cloroplastos también contienen una misteriosa ARN polimerasa codificada por el genoma nuclear de la planta. Las dos ARN polimerasas pueden reconocer y unirse a diferentes tipos de promotores dentro del genoma del cloroplasto. [35] Los ribosomas en los cloroplastos son similares a los ribosomas bacterianos. [22]
Edición de ARN en plástidos [ editar ]
La edición de ARN es la inserción, eliminación y sustitución de nucleótidos en una transcripción de ARNm antes de la traducción a proteína. El ambiente altamente oxidativo dentro de los cloroplastos aumenta la tasa de mutación, por lo que se necesitan reparaciones posteriores a la transcripción para conservar las secuencias funcionales. El editosoma del cloroplasto sustituye a C -> U y U -> C en lugares muy específicos en la transcripción. Esto puede cambiar el codón para un aminoácido o restaurar un pseudogen no funcional agregando un codón de inicio AUG o eliminando un codón de parada UAA prematuro. [36]
El editosoma reconoce y se une a la secuencia cis en sentido ascendente del sitio de edición. La distancia entre el sitio de unión y el sitio de edición varía según el gen y las proteínas involucradas en el editosoma. Cientos de diferentes proteínas PPR del genoma nuclear están involucradas en el proceso de edición del ARN. Estas proteínas consisten en 35 aminoácidos repetidos, cuya secuencia determina el sitio de unión cis para la transcripción editada. [36]
Las plantas terrestres basales, como hepáticas, musgos y helechos, tienen cientos de sitios de edición diferentes, mientras que las plantas con flores suelen tener entre treinta y cuarenta. Las plantas parasitarias como Epifagus virginiana muestran una pérdida en la edición de ARN que resulta en una pérdida de función para los genes de la fotosíntesis. [37]
Orientación e importación de proteínas [ editar ]
El movimiento de tantos genes de cloroplastos al núcleo significa que muchas proteínas de cloroplastos que se suponían debían traducirse en el cloroplasto ahora se sintetizan en el citoplasma. Esto significa que estas proteínas deben dirigirse de nuevo al cloroplasto e importarse a través de al menos dos membranas de cloroplasto. [38]
Curiosamente, alrededor de la mitad de los productos proteicos de los genes transferidos ni siquiera están dirigidos al cloroplasto. Muchos se convirtieron en exaptaciones , asumiendo nuevas funciones como participar en la división celular , enrutamiento de proteínas e incluso resistencia a enfermedades . Unos pocos genes de cloroplastos encontraron nuevos hogares en el genoma mitocondrial, la mayoría se convirtieron en pseudogenesno funcionales , aunque algunos genes de ARNt aún funcionan en la mitocondria . [27] Algunos productos de proteínas de ADN de cloroplastos transferidos se dirigen a la vía secretora [27] (aunque se debe tener en cuenta que muchos plastos secundariosestán limitados por una membrana más externa derivada de la membrana celular del huésped y, por lo tanto, topológicamente fuera de la célula, porque para alcanzar el cloroplasto desde el citosol , debe cruzar la membrana celular , como si se dirigiera al espacio extracelular . En esos casos, las proteínas dirigidas al cloroplasto viajan inicialmente a lo largo de la vía secretora). [39]
Debido a que la célula que adquirió un cloroplasto ya tenía mitocondrias (y peroxisomas , y una membrana celular para la secreción), el nuevo huésped del cloroplasto tuvo que desarrollar un sistema único de direccionamiento de proteínas para evitar que las proteínas del cloroplasto se enviaran al orgánulo equivocado . [38]
Traducción citoplásmica y secuencias de tránsito N-terminales [ editar ]

Los polipéptidos , los precursores de las proteínas , son cadenas de aminoácidos . Los dos extremos de un polipéptido se denominan el término N , o extremo amino , y el extremo C , o extremo carboxilo . [40] Para muchas (pero no todas) [41] proteínas cloroplásticas codificadas por genes nucleares , se añaden péptidos de tránsito escindibles a los extremos N de los polipéptidos, que se utilizan para ayudar a dirigir el polipéptido al cloroplasto para su importación [38] [42](Los péptidos de tránsito N-terminal también se usan para dirigir polipéptidos a las mitocondrias de las plantas ).[43] Las secuencias de tránsito N-terminal también se denominan presencias [38] porque están ubicadas en el extremo "frontal" de un polipéptido: los ribosomassintetizan polipéptidos desde el extremo N hasta el extremo C. [40]
Los péptidos de tránsito de cloroplastos exhiben una gran variación en la longitud y la secuencia de aminoácidos. [42] Pueden tener una longitud de 20 a 150 aminoácidos [38], una longitud inusualmente larga, lo que sugiere que los péptidos de tránsito son en realidad colecciones de dominios con diferentes funciones. [42] péptidos de tránsito tienden a ser cargado positivamente , [38] rica en hidroxilados aminoácidos tales como serina , treonina y prolina , y pobre en ácidos aminoácidos como ácido aspártico y ácido glutámico . [42]En una solución acuosa , la secuencia de tránsito forma una bobina aleatoria. [38]
Sin embargo, no todas las proteínas de cloroplasto incluyen un péptido de tránsito escindible N-terminal. [38]Algunos incluyen la secuencia de tránsito dentro de la parte funcional de la proteína en sí. [38] Algunos tienen su secuencia de tránsito anexada a su extremo C en su lugar. [44] La mayoría de los polipéptidos que carecen de secuencias de orientación N-terminales son los que se envían a la membrana externa del cloroplasto , más uno enviado a la membrana interna del cloroplasto . [38]
Fosforilación, chaperones, y el transporte [ editar ]
Después de que un polipéptido de cloroplasto se sintetiza en un ribosoma en el citosol , la energía de ATP se puede usar para fosforilar , o agregar un grupo fosfato a muchos (pero no a todos) de ellos en sus secuencias de tránsito. [38] La serina y la treonina (ambas muy comunes en las secuencias de tránsito de cloroplastos, que representan el 20-30% de la secuencia) [45] a menudo son los aminoácidos que aceptan el grupo fosfato . [43] [45]La enzima que realiza la fosforilación es específica.para los polipéptidos de cloroplastos, e ignora los destinados a mitocondrias o peroxisomas . [45]
La fosforilación cambia la forma del polipéptido, [45] lo que facilita la unión de las proteínas 14-3-3 al polipéptido. [38] [46] En las plantas, las proteínas 14-3-3 solo se unen a las preproteínas de cloroplastos. [43] También está obligado por la h comer s hock p rotein Hsp70 que mantiene el polipéptido a partir de plegado antes de tiempo. [38] Esto es importante porque evita que las proteínas cloroplastas asuman su forma activa y realicen sus funciones cloroplásticas en el lugar equivocado: el citosol . [43] [46]Al mismo tiempo, tienen que mantener la forma suficiente para que puedan ser reconocidos e importados en el cloroplasto. [43]
La proteína de choque térmico y las proteínas 14-3-3 juntas forman un complejo de guía citosólico que facilita la importación del polipéptido del cloroplasto en el cloroplasto. [38]
Alternativamente, si el péptido de tránsito de una preproteína de cloroplasto no está fosforilado, una preproteína de cloroplasto todavía puede unirse a una proteína de choque térmico o Toc159 . Estos complejos se pueden unir al complejo TOC en la membrana del cloroplasto exterior usando energía GTP . [38]
El translocón en la membrana del cloroplasto exterior (TOC) [ editar ]
El complejo TOC , o t ranslocon en la o uter c membrana hloroplast , es una colección de proteínas que importa preproteínas a través de la envoltura del cloroplasto exterior . Se han identificado cinco subunidades del complejo TOC: dos proteínas de unión a GTP Toc34 y Toc159 , el túnel de importación de proteínas Toc75 , más las proteínas Toc64 [38] y Toc12 . [41]
Las tres primeras proteínas forman un complejo central que consiste en un Toc159, cuatro a cinco Toc34 y cuatro Toc75 que forman cuatro orificios en un disco de 13 nanómetros de diámetro. Todo el complejo del núcleo pesa alrededor de 500 kilodaltons . Las otras dos proteínas, Toc64 y Toc12, están asociadas con el complejo central, pero no forman parte de él. [41]
Toc34 y 33 [ editar ]
![Toc34 de una planta de guisante. Toc34 tiene tres moléculas casi idénticas (mostradas en tonos de verde ligeramente diferentes), cada una de las cuales forma un dímero con una de sus moléculas adyacentes. Parte del sitio de unión a una molécula del PIB se resalta en rosa. [47]](https://en.wikipedia.org/wiki/File:TOC34.png)
Toc34 es una proteína integral en la membrana del cloroplasto exterior que está anclada en ella por su cola C-terminal hidrófoba [48] . [38] [46] Sin embargo, la mayor parte de la proteína, incluido su gran dominio deunión al trifosfato de guanosina (GTP) , se proyecta hacia el estroma. [46]
El trabajo de Toc34 es atrapar algunas preproteínas decloroplasto en el citosol y entregarlas al resto del complejo de TOC. [38] Cuando el GTP , una molécula de energía similar al ATP se adhiere a Toc34, la proteína se vuelve mucho más capaz de unirse a muchas preproteínas de cloroplasto en el citosol . [38]La presencia de preproteínas de cloroplastos hace que Toc34 rompa el GTP en difosfato de guanosina (PIB) y fosfato inorgánico . Esta pérdida de GTP hace que la proteína Toc34 libere la preproteína del cloroplasto y la transfiera a la siguiente proteína TOC. [38]Toc34 luego libera la molécula de PIB agotado, probablemente con la ayuda de un factor de intercambio de PIB desconocido . Un dominio de Toc159 podría ser el factor de intercambio que lleve a cabo la eliminación del PIB. La proteína Toc34 puede tomar otra molécula de GTP y comenzar el ciclo nuevamente. [38]
Toc34 se puede apagar por fosforilación . Una proteína quinasa que se desplaza alrededor de la membrana del cloroplasto exterior puede usar ATP para agregar un grupo fosfato a la proteína Toc34, lo que evita que pueda recibir otra molécula de GTP , lo que inhibe la actividad de la proteína. Esto podría proporcionar una manera de regular la importación de proteínas en los cloroplastos. [38] [46]
Arabidopsis thaliana tiene dosproteínas homólogas , AtToc33 y AtToc34 (The At significa A rabidopsis t haliana ),[38] [46] , cada una de las cuales es aproximadamente un 60% idéntica en secuencia de aminoácidos a Toc34 enguisantes (llamada ps Toc34). [46] AtToc33 es el más común en Arabidopsis , [46] y es el análogo funcionalde Toc34 porque se puede desactivar mediante fosforilación. AtToc34 por otro lado no puede ser fosforilado. [38] [46]
Toc159 [ editar ]
Toc159 es otra subunidad TOC de unión a GTP , como Toc34 . Toc159 tiene tres dominios . En el extremo N-terminal se encuentra el dominio A, que es rico en aminoácidos ácidos y ocupa aproximadamente la mitad de la longitud de la proteína. [38] [48] El A-dominio a menudo se escinde , dejando un 86 kilodalton fragmento llamado Toc86 . [48] En el medio está su dominio de unión a GTP , que es muy similar al dominio de unión a GTP homólogo en Toc34. [38] [48] En el terminal Cel extremo es el dominio M hidrofílico , [38] que ancla la proteína a la membrana externa del cloroplasto. [48]
Toc159 probablemente funciona mucho como Toc34, reconociendo proteínas en el citosol utilizando GTP . Se puede regular a través de la fosforilación , pero por una proteína quinasa diferente a la que fosforila Toc34. [41] Su dominio M forma parte del túnel por el que viajan las preproteínas de cloroplastos, y parece proporcionar la fuerza que impulsa las preproteínas a través de, utilizando la energía de GTP . [38]
Toc159 no siempre se encuentra como parte del complejo TOC, también se ha encontrado disuelto en el citosol . Esto sugiere que podría actuar como un transbordador que encuentra preproteínas de cloroplastos en el citosol y las transporta al complejo TOC. Sin embargo, no hay mucha evidencia directa de este comportamiento. [38]
Se ha encontrado una familia de proteínas Toc159, Toc159 , Toc132 , Toc120 y Toc90 en Arabidopsis thaliana . Varían en la longitud de sus dominios A, que ha desaparecido por completo en Toc90. Toc132, Toc120 y Toc90 parecen tener funciones especializadas en la importación de cosas como preproteínas no fotosintéticas, y no pueden reemplazar a Toc159. [38]
Toc75 [ editar ]

{kind=link}
Toc75 es la proteína más abundante en la envoltura externa del cloroplasto. Es un tubo transmembrana que forma la mayor parte del propio poro de TOC. Toc75 es un canal de barril βrevestido por 16 láminas plegadas . [38] El orificio que forma tiene aproximadamente 2,5 nanómetros de ancho en los extremos y se encoge a aproximadamente 1,4–1,6 nanómetros de diámetro en su punto más estrecho, lo suficientemente ancho para permitir que pasen las preproteínas de cloroplastos parcialmente plegadas. [38]
Toc75 también puede unirse a las preproteínas de cloroplastos, pero es mucho peor que Toc34 o Toc159. [38]
Arabidopsis thaliana tiene múltiples isoformas de Toc75 que se denominan por lasposiciones cromosómicas de los genes que las codifican. AtToc75 III es el más abundante de estos. [38]
El translocón en la membrana interna del cloroplasto (TIC) [ editar ]
El translocon TIC , o t ranslocon en el i nner c hloroplast membrana translocon [38] es otro complejo de proteína que importa proteínas a través de la envoltura del cloroplasto interior . Las cadenas polipeptídicas de cloroplastos a menudo viajan a través de los dos complejos al mismo tiempo, pero el complejo TIC también puede recuperar las preproteínas perdidas en el espacio intermembrana . [38]
Al igual que el translocón TOC , el translocón TIC tiene un complejo de gran núcleo rodeado por algunas proteínas periféricas poco asociadas como Tic110 , Tic40 y Tic21 . [49] El complejo del núcleo pesa alrededor de un millón de daltons y contiene Tic214 , Tic100 , Tic56 y Tic20 I , posiblemente tres de cada uno. [49]
Tic20 [ editar ]
Tic20 es una proteína integral que se cree que tiene cuatro hélices α transmembrana . [38] Se encuentra en el complejo de 1 millón de dalton TIC. [49] Debido a que es similar a bacterianas de aminoácidos transportistas y el mitocondrial proteína importación Tim17 [38] ( t ranslocase en el i nner m itochondrial m embrane ), [50] se ha propuesto para ser parte del canal de importación TIC. [38] No hay in vitroevidencia de esto sin embargo. [38] En Arabidopsis thaliana , se sabe que por aproximadamente cada cinco proteínas Toc75 en la membrana externa del cloroplasto, hay dos proteínas Tic20 I (la forma principal de Tic20 en Arabidopsis ) en la membrana interna del cloroplasto. [49]
A diferencia de Tic214 , Tic100 o Tic56 , Tic20 tiene parientes homólogos en cianobacterias y en casi todos los linajes de cloroplastos, lo que sugiere que evolucionó antes de la primera endosimbiosis del cloroplasto. Tic214 , Tic100 y Tic56 son exclusivos de los cloroplastos de cloroplasto, lo que sugiere que evolucionaron más adelante. [49]
Tic214 [ editar ]
Tic214 es otra proteína compleja del núcleo de las TIC, llamada así porque pesa poco menos de 214 kilodaltons . Tiene una longitud de 1786 aminoácidos y se cree que tiene seis dominios transmembrana en su extremo N-terminal . Tic214 es notable por estar codificado por el ADN del cloroplasto, más específicamente el primer marco de lectura abierto ycf1 . Tic214 y Tic20 juntos forman probablemente la parte del complejo de un millón de daltonTIC que abarca toda la membrana . Tic20 está enterrado dentro del complejo, mientras que Tic214 está expuesto en ambos lados de la membrana interna del cloroplasto . [49]
Tic100 [ editar ]
Tic100 es una proteína de codificación nuclear que tiene una longitud de 871 aminoácidos . Los 871 aminoácidos pesan colectivamente un poco menos de 100 mil daltons , y como la proteína madura probablemente no pierde ningún aminoácido cuando se importa al cloroplasto (no tiene péptido de tránsito escindible ), se llamó Tic100. Tic100 se encuentra en los bordes del complejo de 1 millón de dalton en el lado que mira hacia el espacio intermembrana del cloroplasto . [49]
Tic56 [ editar ]
Tic56 es también una proteína codificada nuclear . La preproteína que codifica su gen tiene una longitud de 527 aminoácidos y pesa cerca de 62 mil daltons ; la forma madura probablemente se somete a un procesamiento que la recorta a algo que pesa 56 mil daltons cuando se importa al cloroplasto. Tic56 está en gran parte incrustado dentro del complejo de 1 millón de dalton. [49]
Tic56 y Tic100 están altamente conservados entre las plantas terrestres, pero no se parecen a ninguna proteína cuya función es conocida. Tampoco tiene ningún dominio transmembrana .
No hay comentarios:
Publicar un comentario