Algoritmos de clasificación
C4.5 es un algoritmo usado para generar un árbol de decision desarrollado por Ross Quinlan.1 C4.5 es una extensión del algoritmo ID3 desarrollado anteriormente por Quinlan. Los árboles de decisión generador por C4.5 pueden ser usados para clasificación, y por esta razón, C4.5 esta casi siempre referido como un clasificador estadístico.
Algoritmo
C4.5 construye árboles de decisión desde un grupo de datos de entrenamiento de la misma forma en que lo hace ID3, usando el concepto de entropía de información. Los datos de entrenamiento son un grupo 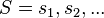 de ejemplos ya clasificados. Cada ejemplo
de ejemplos ya clasificados. Cada ejemplo  es un vector donde
es un vector donde  representan los atributos o características del ejemplo. Los datos de entrenamiento son aumentados con un vector
representan los atributos o características del ejemplo. Los datos de entrenamiento son aumentados con un vector  donde
donde  representan la clase a la que pertenece cada muestra.
representan la clase a la que pertenece cada muestra.
de ejemplos ya clasificados. Cada ejemplo es un vector donde representan los atributos o características del ejemplo. Los datos de entrenamiento son aumentados con un vector donde representan la clase a la que pertenece cada muestra.
En cada nodo del árbol, C4.5 elige un atributo de los datos que más eficazmente dividen el conjunto de muestras en subconjuntos enriquecidos en una clase u otra. Su criterio es el normalizado para ganancia de información (diferencia de entropía) que resulta en la elección de un atributo para dividir los datos. El atributo con la mayor ganancia de información normalizada se elige como parámetro de decisión. El algoritmo C4.5 divide recursivamente en sublistas más pequeñas.
Este algoritmo tiene unos pocos casos base.
- Todas las muestras en la lista pertenecen a la misma clase. Cuando esto sucede, simplemente crea un nodo de hoja para el árbol de decisión diciendo que elija esa clase.
- Ninguna de las características proporciona ninguna ganancia de información. En este caso, C4.5 crea un nodo de decisión más arriba del árbol utilizando el valor esperado de la clase.
- Instancia de la clase previamente no vista encontrada. Una vez más, C4.5 crea un nodo de decisión más arriba en el árbol con el valor esperado.
Pseudocódigo
En pseudocódigo, el algoritmo general para construir árboles de decisión es:2
- Comprobar los casos base
- Para cada atributo a
- Encontrar la ganancia de información normalizada de la división de a
- Dejar que a_best sea el atributo con la ganancia de información normalizada más alta
- Crear un nodo de decisión que divida a_best
- Repetir en las sublistas obtenidas por división de a_best, y agregar estos nodos como hijos de nodo
Implementaciones
J48 es una implementación open source en lenguaje de programación Java del algoritmo C4.5 en la herramienta weka de minería de datos.
Mejoras desde el algoritmo ID3
En C4.5 se hicieron un número de mejoras a ID3. Algunas de ellas son:
- Manejo de ambos atributos continuos y discretos - A fin de manejar atributos continuos, C4.5 crea un umbral y luego se divide la lista en aquellos cuyo valor de atributo es superior al umbral y los que son menores o iguales a él.3
- Manejo de los datos de formación con valores de atributos faltantes - C4.5 permite valores de los atributos para ser marcado como? para faltantes. Los valores faltantes de los atributos simplemente no se usa en los cálculos de la ganancia y la entropía.
- Manejo de atributos con costos diferentes.
- Podando árboles después de la creación - C4.5 se remonta a través del árbol una vez que ha sido creado e intenta eliminar las ramas que no ayudan, reemplazándolos con los nodos de hoja.
Mejoras en Algoritmo C5.0/See5
Quinlan continuó con la creación del C5.0 y el See5 (C5.0 para Unix / Linux, See5 para Windows) con fines comerciales. C5.0 ofrece una serie de mejoras en el C4.5. Algunas de estas son:4
- Velocidad - C5.0 es significativamente más rápido que el C4.5 (varios órdenes de magnitud)
- El uso de memoria - C5.0 es más eficiente que el C4.5
- Árboles de decisión más pequeños - C5.0 obtiene resultados similares a C4.5 con árboles de decisión mucho más pequeños.
- Soporte para boosting - Boosting mejora los árboles y les da una mayor precisión.
- Ponderación - C5.0 le permite ponderar los distintos casos y tipos de errores de clasificación.
- Winnowing - una opción automática de C5.0 winnows los atributos para eliminar aquellos que pueden ser de poca ayuda.
algoritmo ID3 es utilizado dentro del ámbito de la inteligencia artificial. Su uso se engloba en la búsqueda de hipótesis o reglas en él, dado un conjunto de ejemplos.
El conjunto de ejemplos deberá estar conformado por una serie de tuplas de valores, cada uno de ellos denominados atributos, en el que uno de ellos, ( el atributo a clasificar ) es el objetivo, el cual es de tipo binario ( positivo o negativo, sí o no, válido o inválido, etc. ).
De esta forma el algoritmo trata de obtener las hipótesis que clasifiquen ante nuevas instancias, si dicho ejemplo va a ser positivo o negativo.
ID3 realiza esta labor mediante la construcción de un árbol de decisión.
Los elementos son:
- Nodos: Los cuales contendrán atributos.
- Arcos: Los cuales contienen valores posibles del nodo padre.
- Hojas: Nodos que clasifican el ejemplo como positivo o negativo.
El algoritmo
Id3(Ejemplos, Atributo-objetivo, Atributos )
Si todos los ejemplos son positivos devolver un nodo positivo
Si todos los ejemplos son negativos devolver un nodo negativo
Si Atributos está vacío devolver el voto mayoritario del valor del atributo objetivo en
Ejemplos
En otro caso
Sea A Atributo el MEJOR de atributos
Para cada v valor del atributo hacer
Sea Ejemplos(v) el subconjunto de ejemplos cuyo valor de atributo A es v
Si Ejemplos(v) esta vacío devolver un nodo con el voto mayoritario del
Atributo objetivo de Ejemplos
Sino Devolver Id3(Ejemplos(v), Atributo-objetivo, Atributos/{A})
Obsérvese que la construcción del árbol se hace forma recursiva, siendo las tres primeras líneas y la penúltima los casos base que construyen los nodos hojas.
Elección del mejor atributo
La elección del mejor atributo se establece mediante la entropía. Eligiendo aquel que proporcione una mejor ganancia de información. La función elegida puede variar, pero en su forma más sencilla es como esta:

Donde p es el conjunto de los ejemplos positivos, n el de los negativos y d el total de ellos. Se debe establecer si el logaritmo es positivo o negativo
Un ejemplo
| Ej. | Cielo | Temperatura | Humedad | Viento | Jugar tenis |
|---|---|---|---|---|---|
| D1 | Sol | Alta | Alta | Débil | - |
| D2 | Sol | Alta | Alta | Fuerte | - |
| D3 | Nubes | Alta | Alta | Débil | + |
| D4 | Lluvia | Suave | Alta | Débil | + |
| D5 | Lluvia | Baja | Normal | Débil | + |
| D6 | Lluvia | Baja | Normal | Fuerte | - |
| D7 | Nubes | Baja | Normal | Fuerte | + |
| D8 | Sol | Suave | Alta | Débil | - |
| D9 | Sol | Baja | Normal | Débil | + |
| D10 | Lluvia | Suave | Normal | Débil | + |
| D11 | Sol | Suave | Normal | Fuerte | + |
| D12 | Nubes | Suave | Alta | Fuerte | + |
| D13 | Nubes | Alta | Normal | Débil | + |
| D14 | Lluvia | Suave | Alta | Fuerte | - |
En ese caso el árbol finalmente obtenido sería así:
Cielo
/ | \
/ | \
Soleado / Nublado \ Lluvia
/ | \
/ +
Humedad Viento
/ \ | \
/ \ | \
Alta/ \ Normal Fuerte | \ Débil
/ \ | \
- + - +
No hay comentarios:
Publicar un comentario