La región flanqueante 5 ' es una región de ADN que está adyacente al extremo 5' del gen. La región flanqueante 5 'contiene el promotor , y puede contener potenciadores u otros sitios de unión a proteínas. Es la región del ADN que no se transcribe en el ARN. No debe confundirse con la región no traducida 5 ' , esta región no se transcribe en ARN , ni se traduce en una proteína funcional . Estas regiones funcionan principalmente en la regulación de la transcripción de genes . Las regiones flanqueantes 5 'difieren entre procariotasy eucariotas .

Elementos eucariotas [ editar ]
En los eucariotas, la región flanqueante 5 'tiene un conjunto complejo de elementos reguladores como potenciadores , silenciadores y promotores . El elemento promotor principal en eucariotas es la caja TATA . Otros elementos promotores encontrados en las regiones flanqueantes 5 'eucariotas incluyen elementos iniciadores , elementos promotores del núcleo en sentido descendente , caja CAAT y caja GC . [1]
Mejorador [ editar ]
Los potenciadores son secuencias de ADN que se encuentran en las regiones flanqueantes 5 'de los genes eucarióticos que afectan la transcripción. Si un factor de transcripción se une a un potenciador en una región flanqueante 5 ', la cadena de ADN se dobla de manera que el factor de transcripción que se une al potenciador también puede unirse al promotor de un gen. Esto conduce al reclutamiento de ARN polimerasa y la interacción con los factores de transcripción y el promotor, y una tasa de transcripción global más alta que el nivel basal. [2]Aunque los potenciadores suelen estar presentes antes del sitio de inicio de la transcripción , pueden estar presentes en cualquier lugar del gen de interés o alrededor de este. [3]
Silenciador [ editar ]
Los silenciadores son secuencias de ADN que se encuentran en la región flanqueante 5 'de los genes eucarióticos, que ayudan en el silenciamiento de un gen. Se pueden encontrar corriente arriba, corriente abajo o dentro del gen de interés. [3] Cuando los represores se unen a los silenciadores, actúan de manera similar como potenciadores y se inclinan para evitar la interacción de la ARN polimerasa con los promotores. Esto silencia el gen y por lo tanto el gen no se expresará en la célula.
Caja TATA [ editar ]
La caja TATA está presente en todos los genes que se transcriben mediante la ARN polimerasa II , que es la mayoría de los genes eucarióticos. La unión de la caja TATA con la proteína de unión a TATA inicia la formación de un complejo de factor de transcripción. A esto le sigue la unión del factor de transcripción TFIID , que luego recluta TFIIB , TFIIF , ARN polimerasa II y TFIIH (en ese orden) para formar un complejo de iniciación . [1]Normalmente es de 10 nucleótidos de largo, y está presente de 30 a 20 nucleótidos en sentido ascendente desde el sitio de inicio de la transcripción, en elregión promotora del núcleo . [2]
CAAT box [ editar ]
La caja CAAT es un elemento crucial de la región flanqueante 5 'de los genomas eucarióticos. Un factor de transcripción específico llamado proteína de unión a CAAT se une a esta región y ayuda en la transcripción en eucariotas. Normalmente tiene una longitud de 10 nucleótidos , y está presente de -80 a -70 nucleótidos ensentido ascendente desde el sitio de inicio de la transcripción, en la región del promotor proximal . [2]
Elementos procariotas [ editar ]
Los procariotas solo tienen tres elementos promotores: dos elementos están presentes -35 y -10 nucleótidos en sentido ascendente del sitio de inicio de la transcripción, y el tercero está directamente en la parte superior del sitio de inicio de la transcripción. Los elementos del promotor procariótico no son idénticos entre las especies, pero tienen una secuencia de consenso de 6 nucleótidos cada uno. La ARN polimerasa bacteriana se une a estas regiones para alinearse y comenzar la transcripción. Las secuencias promotoras que difieren de la secuencia de consenso generalmente se transcriben de manera menos eficiente. Además, las mutaciones inducidas en estas secuencias promotoras -35 y -10 han demostrado ser perjudiciales para la transcripción. [4]
Polimorfismos [ editar ]
Los SNP flanqueantes son polimorfismos de un solo nucleótido (SNP) que aparecen en la región flanqueante. Los polimorfismos en esta región pueden llevar a cambios en la regulación de la transcripción . [5] También se han asociado con una serie de enfermedades. Una inserción de 12 pares de bases en la región flanqueante 5 'del gen de la cistatina B se ha relacionado con algunos individuos con enfermedad de Unverricht-Lundborg . [6] Los polimorfismos en la región flanqueante 5 'del gen DRD4 se han relacionado con TDAH , esquizofrenia y abuso de metanfetamina . [7] Inserciones y supresiones.en la región 5 'flanqueante del gen de la insulina se han asociado a la diabetes tipo 2 . [8] [9] Los polimorfismos en la región flanqueante 5 'del gen que codifica la oxitocina se han vinculado a mutaciones en la función del promotor, lo que finalmente conduce a posibles trastornos relacionados con la alteración de los niveles y la funcionalidad de la oxitocina.
El patógeno Proyecto Genoma 100K fue lanzado en julio de 2012 por Bart Weimer (UC Davis) como académico, público y privada. [1] Su objetivo es secuenciar los genomas de 100,000 microorganismos infecciosos para crear una base de datos de secuencias del genoma bacteriano para uso en salud pública, detección de brotes y detección de patógenos bacterianos. Esto acelerará el diagnóstico de enfermedades transmitidas por los alimentos y acortará los brotes de enfermedades infecciosas. [2]
El proyecto 100K Pathogen Genome es un proyecto de colaboración público-privada para secuenciar los genomas de 100,000 microorganismos infecciosos. El Proyecto del Genoma 100K proporcionará una hoja de ruta para el desarrollo de pruebas para identificar patógenos y rastrear sus orígenes más rápidamente.
Los socios anunciados en el lanzamiento del proyecto fueron UC Davis , Agilent Technologies y la Administración de Drogas y Alimentos de los EE. UU., Con los Centros para el Control y la Prevención de Enfermedades de los EE. UU. Y el Departamento de Agricultura de EE. UU. Destacados como colaboradores. A medida que el proyecto avanzó, la asociación ha evolucionado para incluir o reemplazar a estos socios fundadores. El Proyecto de Genoma de Patógenos 100K fue seleccionado por el Consorcio de Seguridad Alimentaria IBM / Mars para las secuencias metagenómicas.
El proyecto 100K Pathogen Genome está llevando a cabo una secuenciación de última generación (NGS) de alto rendimiento para investigar los genomas de los microorganismos objetivo , y la secuenciación del genoma completo se llevará a cabo en un pequeño número de microorganismos para su uso como genoma de referencia. La mayoría de las cepas bacterianas serán secuenciadas y ensambladas como genomas de tiro; sin embargo, el proyecto también ha producido genomas cerrados para una variedad de patógenos entéricos en el bioproyecto 100K. [3] Los datos de este proyecto también están disponibles para su descarga en el sitio web 100K Pathogen Genome Project [1] .
Esta estrategia permite la colaboración mundial para identificar conjuntos de biomarcadores genéticos asociados con rasgos patógenos importantes. Este proyecto de patógeno microbiano de cinco años dará como resultado una base de datos pública y gratuita que contiene la información de la secuencia del genoma de cada patógeno. Las secuencias de genes completadas se almacenarán en la base de datos pública del Centro Nacional de Información de Biotecnología ( NCBI ) de los Institutos Nacionales de la Salud ( NIH ) . [4] Usando la base de datos, los científicos podrán desarrollar nuevos métodos para controlar las bacterias causantes de enfermedades en la cadena alimentaria.
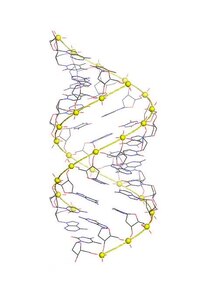
El A-ADN es una de las posibles estructuras de doble hélice que el ADNpuede adoptar. A-DNA se piensa que es una de las tres estructuras helicoidales dobles biológicamente activos junto con B-ADN y ADN-Z . Es una doble hélice para diestros bastante similar a la forma más común de B-DNA, pero con una estructura helicoidal más corta y compacta cuyos pares de bases no son perpendiculares al eje helicoidal como en B-DNA. Fue descubierta por Rosalind Franklin , quien también nombró las formas A y B. Ella demostró que el ADN se introduce en la forma A cuando se encuentra en condiciones de deshidratación. Tales condiciones se usan comúnmente para formar cristales, y muchas estructuras de cristal de ADN están en la forma A. [1] La misma conformación helicoidal ocurre en los ARN de doble cadena, y en las hélices dobles híbridas ADN-ARN.
Estructura [ editar ]
El ADN-A es bastante similar al ADN-B, dado que es una doble hélice para diestros con surcos mayores y menores. Sin embargo, como se muestra en la tabla de comparación a continuación, hay un ligero aumento en el número de pares de bases (pb) por turno (lo que resulta en un menor ángulo de giro) y un menor aumento por par de bases (lo que hace que el A-ADN sea del 20-25%). más corto que el B-ADN). El surco mayor de A-DNA es profundo y estrecho, mientras que el surco menor es ancho y poco profundo. El ADN-A es más amplio y aparentemente más comprimido a lo largo de su eje que el ADN-B. [2]
Geometrías de comparación de las formas de ADN más comunes [ editar ]


| Atributo de geometría: | Una forma | Forma B | Forma en Z |
|---|---|---|---|
| Sentido de hélice | diestro | diestro | zurdo |
| Unidad de repetición | 1 pb | 1 pb | 2 pb |
| Rotación / pb | 32.7 ° | 34.3 ° | 60 ° / 2 |
| Media pb / turno | 11 | 10.5 | 12 |
| Inclinación de bp al eje. | + 19 ° | −1.2 ° | −9 ° |
| Subida / pb a lo largo del eje | 2.6 Å (0.26 nm) | 3.4 Å (0.34 nm) | 3.7 Å (0.37 nm) |
| Ascenso / giro de la hélice | 28,6 Å (2,86 nm) | 35,7 Å (3,57 nm) | 45,6 Å (4,56 nm) |
| Giro medio de la hélice | + 18 ° | + 16 ° | 0 ° |
| Ángulo de glicosilo | anti | anti | pirimidina: anti, purina: syn |
| Nucleótido fosfato a fosfato a distancia | 5,9 Å | 7.0 Å | C: 5.7 Å, G: 6.1 Å |
| Azúcar pucker | C3'-endo | C2'-endo | C: C2'-endo, G: C3'-endo |
| Diámetro | 23 Å (2,3 nm) | 20 Å (2.0 nm) | 18 Å (1.8 nm) |
Función biológica [ editar ]
La deshidratación del ADN lo lleva a la forma A, y esto aparentemente protege el ADN en condiciones tales como la desecación extrema de las bacterias. [3] La unión a proteínas también puede eliminar el solvente del ADN y convertirlo en la forma A, como lo revela la estructura de un virus con forma de varilla. [4]
Se ha propuesto que los motores que empaquetan ADN bicatenario en bacteriófagos explotan el hecho de que el ADN-A es más corto que el ADN-B, y que los cambios conformacionales en el ADN en sí son la fuente de las grandes fuerzas generadas por estos motores. [5] La evidencia experimental de que el A-ADN es un intermediario en el empaquetamiento de biomotores virales proviene de las mediciones de transferencia de energía de resonancia de Förster de doble tinte que muestran que el B-ADN se acorta en un 24% en un intermedio de forma A estancado ("triturado"). [6] [7] En este modelo, la hidrólisis de ATP se utiliza para impulsar cambios conformacionales de proteínas que, de manera alternativa, deshidratan y rehidratan el ADN, y el ciclo de acortamiento / alargamiento del ADN se acopla a un ciclo de agarre / liberación de proteína-ADN para generar el movimiento hacia adelante que mueve el ADN hacia la cápside. .
No hay comentarios:
Publicar un comentario